
名刺を画像から読み取り、ChatGPTで解析するシステムの構築 その2 -AWSとGCPの使い方も紹介
目次
はじめに
前回の記事では、名刺情報の読み取りシステムの準備段階についてChatGPT APIを用いた方法について解説しました。そして今回は、予告通りOCR(光学式文字認識)の技術を活用して、名刺情報を読み取る方法についてお話しします。
現在、多くの営業職の方が頻繁に名刺を交換する中で、これを効率的に整理・共有する仕組みへのニーズが高まっています。従来は手作業で入力したり、整理したりする負担がありましたが、OCRの技術を取り入れることで、迅速かつ正確に名刺の情報を登録・更新することが可能になります。今回の記事では、OCRをどのように導入し、名刺から必要な情報を抽出するかを実現する方法について、具体的なプロセスやポイントをご紹介します。
OCR(光学式文字認識)とは
OCR(光学文字認識)は、画像データ内の文字を認識し、テキストデータに変換する技術です。主に紙に書かれた文字をデジタル化するために使用され、スキャナーで読み取った紙文書をデジタルデータとして保存し、検索や編集が可能になります。OCRを使うことで、手入力の手間を省き、文書の検索性を向上させることができ、業務効率化を加速させています。
Amazon Web Services(AWS)実装編
OCR(光学文字認識)のサービスは多くの企業が提供していますが、個人的には世界3大クラウドである、以下の3つを利用するのがおすすめです。
- Amazon Web Services(AWS)
- Microsoft Azure(Azure)
- Google Cloud Platform(GCP)
これらのサービスを選ぶ理由はさまざまですが、大きな理由は、この3つのクラウドが世界で広く使われており、日本でも多くのユーザーがいることです。そのため、困ったときに公式ドキュメントや個人ブログなど、情報を簡単に見つけることができます。また、これらのクラウドサービスは他にもさまざまなサービスを提供しているので、今後のプロジェクトに役立つアイデアが得られる点も魅力です。
今回は、その中でもシェア率が一番高いAmazon Web Services(AWS)を使ってみたいと思います。AWSは、一般の人でも一度は耳にしたことがあるくらい広く利用されており、例えば、某大手スマホゲームにも使われているほど、非常にメジャーなサービスです。
AWS上での設定
今回はAmazon Web Services(AWS)にある、ストレージサービスのAmazon S3 の画像・動画分析ができるAmazon Rekognition を使用します。
最初に思い浮かべるのは、ローカルに保存している画像を直接Amazon Rekognitionに渡して、文字認識を行うことだと思います。私も最初はそう考えました(笑)。しかし、実はAWSでは直接Amazon Rekognitionに画像をアップロードすることはできません。画像を使うには、一度ストレージサービスのAmazon S3に保存してから、その画像をAmazon Rekognitionで分析する必要があります。
正直、この流れはややこしくて面倒だと感じるかもしれません。初めてAWSを触る方には少し混乱するかもしれませんが、AWSの仕組みに従えばスムーズに進めることができます。この記事では、AWSを使ったことがない方でも理解できるように、ステップごとに丁寧に説明しますので、安心して設定を進めていきましょう。
1.まずはこのページからアカウントを作成してください。
2.アカウントの作成が完了したら、このリンクから右上にある「ユーザーの作成」を押下して、ユーザーを作成してください
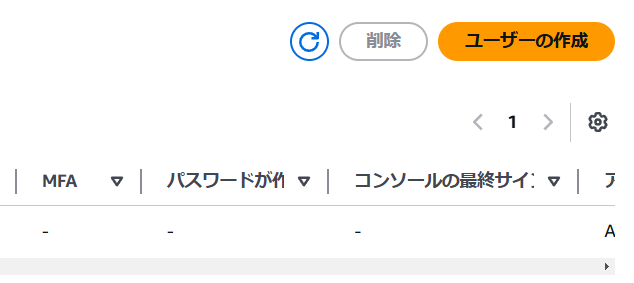
3.この画面に遷移するので、「IAM ユーザーを作成します」を選択して完了したら「次へ」ボタンを押下してください。
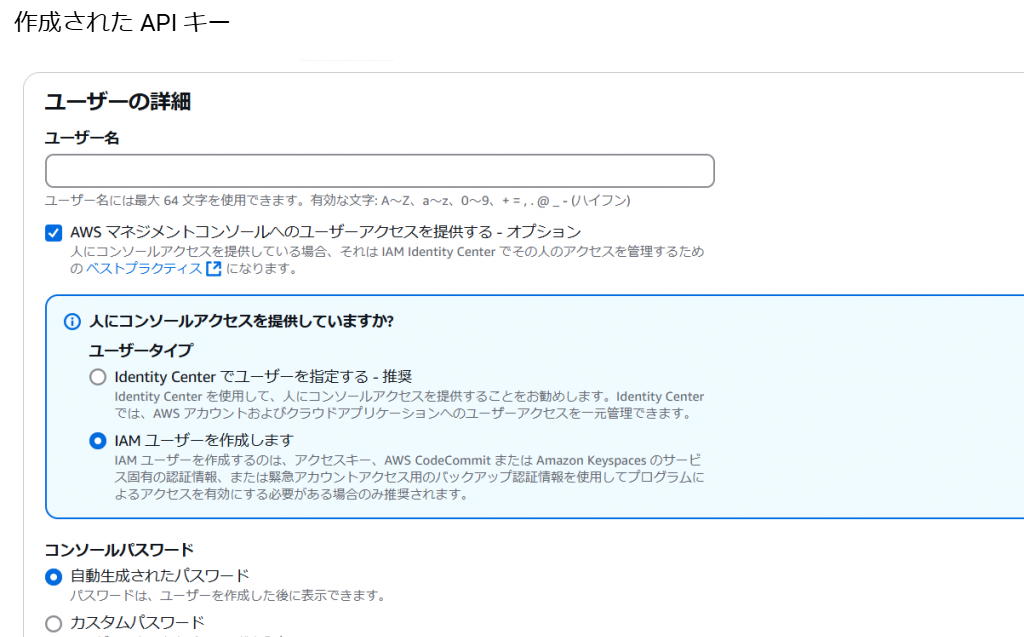
4.「次へ」を押下してください
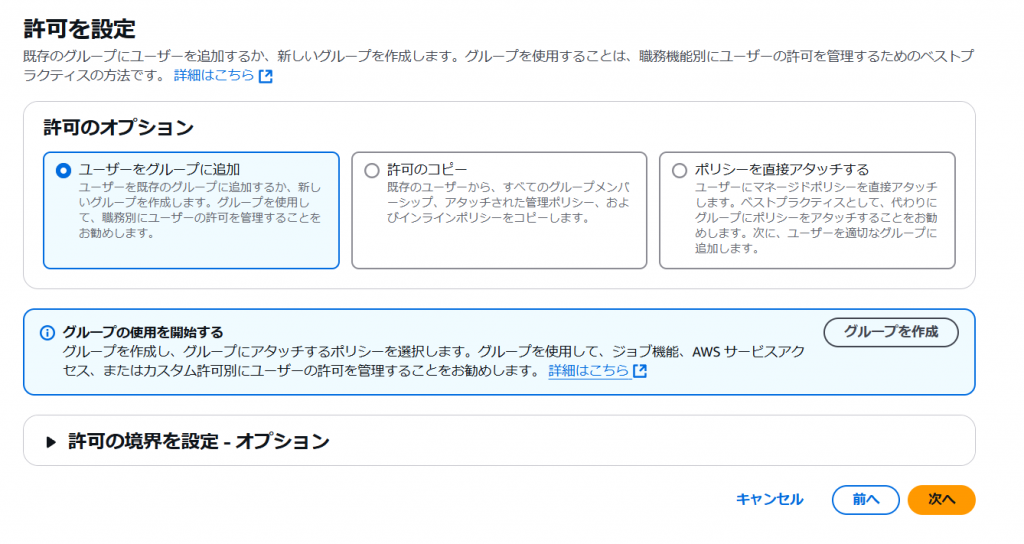
5.完了したら「.csv ファイルをダウンロード」を押下してください。
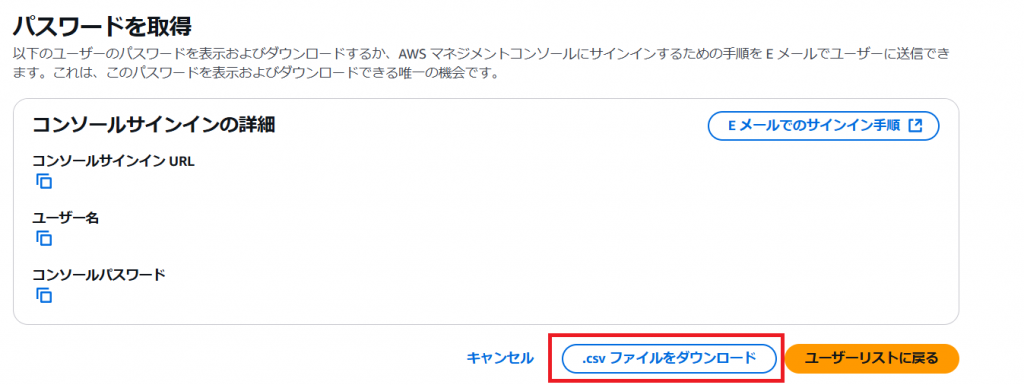
6.次にこのリンクから、さきほど作成したユーザーを選択してください
7.遷移先の画面に「アクセスキーを作成」を押下してください

8.「コマンドラインインターフェイス (CLI)」を選択して、「次へ」ボタンを押下してください

9.「アクセスキーを作成」ボタンを押下してください

10.完了したら「.csv ファイルをダウンロード」と「完了」を押下してください。

11.次にこのリンクからAWS CLIをインストールしてください
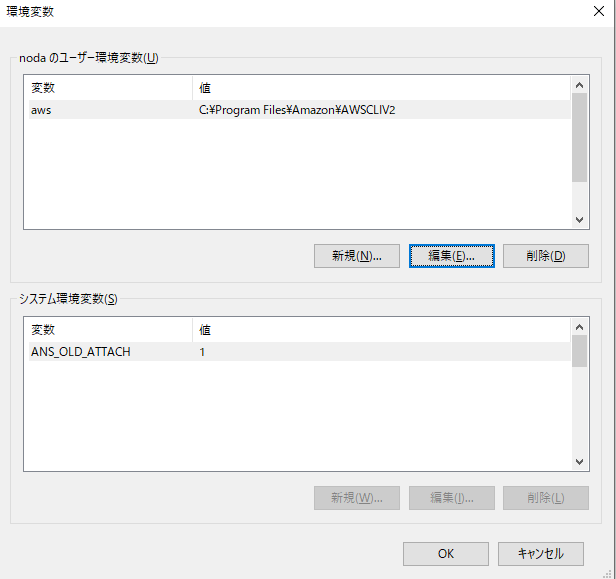
12.インストールが完了したら、Windowsの環境変数にAWS CLIのディレクトリを追加してください。
13.Windowsのコマンドプロンプトで、このようなコマンドを入れて以下のようにリクエストが返ってきたら成功です。
C:\Users\Username>aws
usage: aws [options] <command> <subcommand> [<subcommand> ...] [parameters]
To see help text, you can run:
aws help
aws <command> help
aws <command> <subcommand> help
aws: error: the following arguments are required: command
14.次にコマンドプロンプトで、このコマンドを実行してください
aws configureAWS Access Key ID 、AWS Secret Access Key 、Default region name [ap-northeast-1]、Default output formatが聞かれます。Access Key ID 、AWS Secret Access Keyは10.で取得した情報を入力してください。Default region name [ap-northeast-1]はap-northeast-1、Default output formatはjsonを入力してください。AWS CLIのConfigファイルは、C:\Users\ユーザー名\.awsにあるので確認してください。これでAWS上での設定は完了しました。
Amazon S3に画像を保存
次に、ストレージサービスであるAmazon S3に画像をアップロードする方法を紹介します。その前に、AWS側でいくつかの準備が必要ですので、そちらを説明します。
1.まずはAWSのコンソール画面に行き、左上にある検索窓で「S3」と入力してAmazon S3 にアクセスしてください。

2.次に右上にある都市名を今回選んだリージョンのap-northeast-1である「東京」を選んでください。
3.画像を保存するには「バケット」を作成する必要があります。バケットとは、簡単に言うと、画像を入れるための「フォルダ」のようなものです。「バケットを作成」ボタンを押して、新しいバケットを作成しましょう。

4.遷移先の画面で、必ずをバケット名を入力してください。完了したら「バケットを作成」ボタンを押下してください。
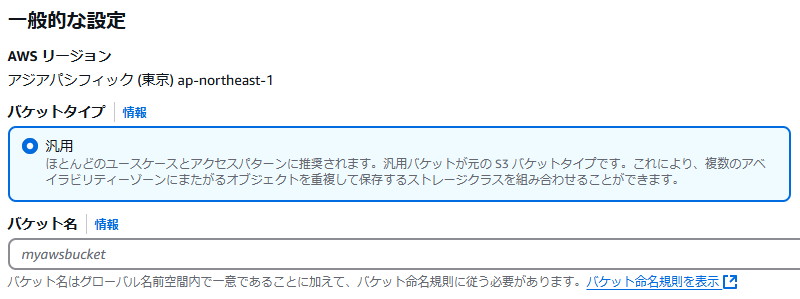
5.汎用バケットに先ほど作成したものが表示されていれば成功です。
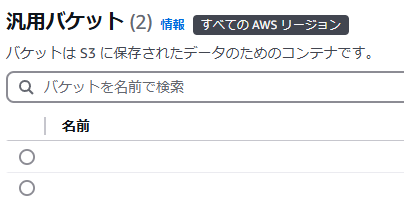
今回、公式ドキュメントを見て以下のコードを書きました。コードの実行前にpipを使用してboto3をインストールしてください。
pip install boto3import boto3
# アップロードする画像ファイルのパス
IMAGE_FILE_PATH = r"C:\Users\Username\Desktop\meishi_card.png"
# アップロード先のS3バケット名
BUCKET_NAME = "[4.で表示されているバケット名]"
# S3バケット内での保存先ファイル名
S3_FILE_NAME = "meishi_card.png"
# AWSリージョン名
AWS_REGION = "ap-southeast-1" # 例: 東京
# AWS CLIのプロファイル名
AWS_PROFILE_NAME = "default" # 使用するプロファイル名を指定
def upload_to_s3(file_path: str, bucket_name: str, s3_file_name: str, region_name: str, profile_name: str) -> None:
"""
ローカルファイルを指定したS3バケットにアップロードする関数
:param file_path: アップロードするローカルのファイルパス
:param bucket_name: アップロード先のS3バケット名
:param s3_file_name: S3バケット内での保存先ファイル名
:param region_name: AWSリージョン名
:param profile_name: 使用するAWS CLIのプロファイル名
"""
# 指定されたプロファイルを使用してセッションを作成
session = boto3.Session(profile_name=profile_name, region_name=region_name)
# S3クライアントの初期化
s3 = session.client('s3')
try:
# S3にファイルをアップロード
s3.upload_file(file_path, bucket_name, s3_file_name)
print(f"File successfully uploaded to {bucket_name}/{s3_file_name} in {region_name} region")
except Exception as e:
print(f"Error occurred: {e}")
if __name__ == "__main__":
# 画像をS3にアップロード
upload_to_s3(IMAGE_FILE_PATH, BUCKET_NAME, S3_FILE_NAME, AWS_REGION, AWS_PROFILE_NAME)
このコードを実行しましたが、今度は下記のエラーが出ました。
Error occurred: Failed to upload C:\Users\Username\Desktop\meishi_card.png to [4.で表示されているバケット名]/meishi_card.png: An error occurred (AccessDenied) when calling the PutObject operation: User: arn:aws:iam::××××××××××××××××:user/×××× is not authorized to perform: s3:PutObject on resource: "arn:aws:s3:::[4.で表示されているバケット名]/meishi_card.png" because no identity-based policy allows the s3:PutObject actionこのエラーが発生した理由は、AWSで必要な「許可ポリシー」が設定されていないためです。簡単に言うと、現在使っているユーザー(または役割)には、S3バケットにファイルをアップロードする権限が与えられていないということです。AWSでは、ユーザーがどの操作を実行できるかを制御するために「ポリシー」を使用します。このポリシーが正しく設定されていないと、操作が拒否されることになります。よって次から許可ポリシーの設定方法を紹介します。
1.次にこのリンクから、さきほど作成したユーザーを選択してください
2.「許可を追加」⇒「インラインポリシー」を押下してください

3.サービスを選択してください。今回は「S3」を選んでください。そして「リスト」カテゴリからListBucket、「読み取り」カテゴリからGetObject、「書き込み」カテゴリからPutObjectを選択してください。
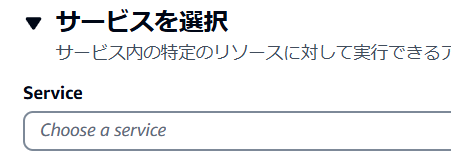
4.リソースも選択してください。「特定」を選んで、ARN を追加をクリックしてください。

5.Resource bucket nameに先ほど作成したバケット名を、Resource object nameには任意の object nameのチェックボックスを選択してください。完了したら「ARNを追加」してください。この操作は、特定のバケットやオブジェクトに対して、アクセス権限を付与するための設定です。具体的には、この操作を通じて「どのバケットやオブジェクトに対して、どのような操作を許可するか」をAWSに対して明示しています。
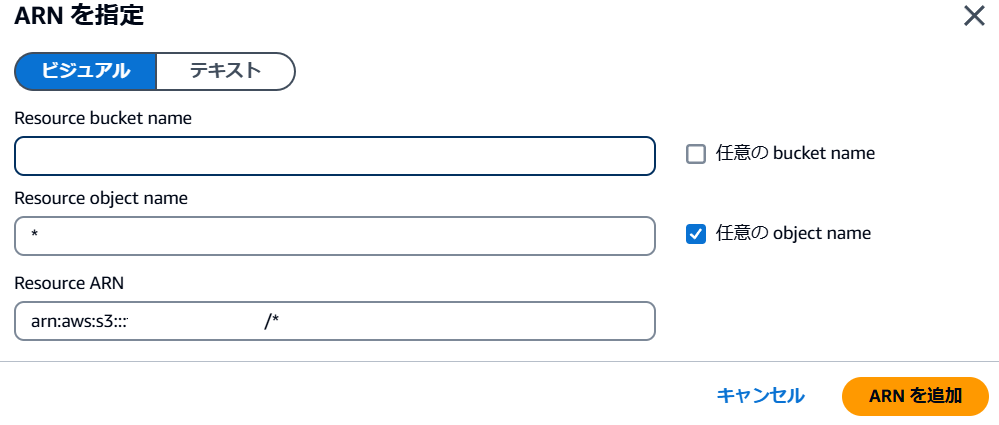
6.終わったら下部にある「次へ」ボタンを押下します。
7.ポリシー名を入力したら、「ポリシーの作成」ボタンを押下してください。これで完了です。

先ほどのポリシーを追加し、再度コードを実行すると、以下のようなメッセージが表示されれば成功です。
File successfully uploaded to ×××××××××/meishi_card.png in ap-southeast-1 regionAmazon Rekognitionで文字起こしをする
次は、Amazon Rekognition の許可ポリシーを設定します。先ほど紹介した許可ポリシーの設定方法を参考にしてください。今回はサービスとして 「Rekognition」 を選択し、アクションには 「読み取り」カテゴリから DetectText を選択 してください。なお、この設定では リソースを個別に選択することはできませんので、その点に注意してください。
なお今回使用したコードはこちらです。
import boto3
# アップロードする画像ファイルのパス
IMAGE_FILE_PATH = r"C:\Users\Username\Desktop\meishi_card.png"
# アップロード先のS3バケット名
BUCKET_NAME = "[4.で表示されているバケット名]"
# S3バケット内での保存先ファイル名
S3_FILE_NAME = "meishi_card.png"
# AWSリージョン名
AWS_REGION = "ap-southeast-1" # 例: 東京
# AWS CLIのプロファイル名
AWS_PROFILE_NAME = "default" # 使用するプロファイル名を指定
def upload_to_s3(file_path: str, bucket_name: str, s3_file_name: str, region_name: str, profile_name: str) -> None:
"""
ローカルファイルを指定したS3バケットにアップロードする関数
:param file_path: アップロードするローカルのファイルパス
:param bucket_name: アップロード先のS3バケット名
:param s3_file_name: S3バケット内での保存先ファイル名
:param region_name: AWSリージョン名
:param profile_name: 使用するAWS CLIのプロファイル名
"""
# 指定されたプロファイルを使用してセッションを作成
session = boto3.Session(profile_name=profile_name, region_name=region_name)
# S3クライアントの初期化
s3 = session.client('s3')
try:
# S3にファイルをアップロード
s3.upload_file(file_path, bucket_name, s3_file_name)
print(f"File successfully uploaded to {bucket_name}/{s3_file_name} in {region_name} region")
except Exception as e:
print(f"Error occurred: {e}")
def detect_text(photo, bucket, region, profile_name):
"""
S3バケット内の画像からテキストを検出する関数
:param photo: 画像ファイル名
:param bucket: S3バケット名
:param region: AWSリージョン名
:param profile_name: 使用するAWS CLIのプロファイル名
"""
# 指定されたプロファイルを使用してセッションを作成
session = boto3.Session(profile_name=profile_name, region_name=region)
client = session.client('rekognition')
# Rekognitionのdetect_text APIを実行
response = client.detect_text(Image={'S3Object': {'Bucket': bucket, 'Name': photo}})
# 検出されたテキストの表示
textDetections = response['TextDetections']
print('Detected text\n----------')
for text in textDetections:
print(text['DetectedText']) # DetectedTextのみ表示
return len(textDetections)
if __name__ == "__main__":
# 画像をS3にアップロード
upload_to_s3(IMAGE_FILE_PATH, BUCKET_NAME, S3_FILE_NAME, AWS_REGION, AWS_PROFILE_NAME)
# テキスト検出を実行
text_count = detect_text(S3_FILE_NAME, BUCKET_NAME, AWS_REGION, AWS_PROFILE_NAME)
print("Text detected: " + str(text_count))
今回は、先ほど使用した画像アップロードのコードも含めていますが、すでに画像を S3 にアップロード済みの場合は、upload_to_s3 関数は不要です。今回はサンプルとして名刺の画像を使用し、コードを実行しました。
5<
1%
to
33
t B
T000-0000
ООООК» 4F
TEL 03-0000-1234 FAX 03-0000-5678
090-0000-5678
X-NPKLX sample@raksul.com
-42-2 http://raksul.comしかし、うまくテキストを読み取ることができませんでした。最初は「Amazon Rekognition の OCR 機能が使えないのでは?」と思いましたが、公式ドキュメントを確認したところ、次のように記載がありました。
Amazon Rekognition は英語、アラビア語、ロシア語、ドイツ語、フランス語、イタリア語、ポルトガル語、スペイン語の単語を検出するように設計されています。
つまり、日本語は未対応 ということです。残念ながら、Amazon Rekognition では日本語テキストを読み取ることができないようです。ちょっと残念ですね…。
Google Cloud Platform(GCP)実装編
Amazon Web Services(AWS)のAmazon Rekognitionがうまくいかなかったため、次はGoogle Cloud Platform(GCP)のCloud Vision APIを試すことにしました。このAPIは日本語を含む多くの言語に対応しています。対応している言語は非常に豊富なので、詳しく知りたい方は公式ドキュメントをチェックしてみてください。この章では、初心者でもわかりやすいようにCloud Vision APIについて説明していきます。サービスの基本的な使い方を順を追って解説します。
GCP上での設定
1.まずはGoogle Cloud Platform(GCP)にアクセスしてください
2.以下の画面からプロジェクトを作成してください
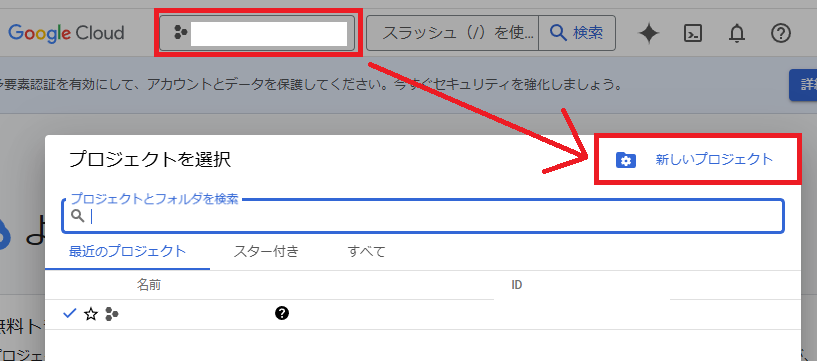
3.作成が終わったら今回使用するプロジェクトを選択してください
3.画面の上部にある検索窓から「Cloud Vision」と入力して、Cloud Vision APIを選択してください
4.「有効にする」ボタンを押下してください

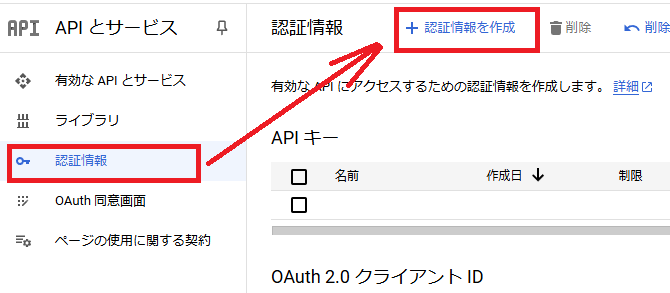
5.下記の画面に遷移するので、「認証情報」と「認証情報を作成」ボタンを押下します
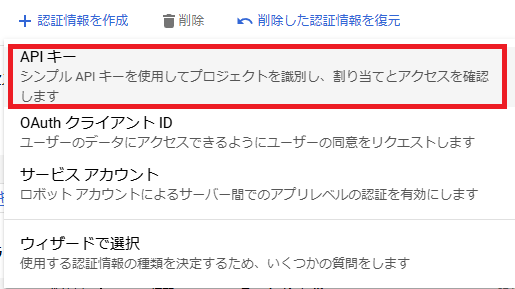
6.APIキーを選択してください
7.APIキーが生成されました。このキーは絶対に外部に公開しないでください

Cloud Vision APIで文字起こしをする
Cloud Vision APIでは、AWSのように画像を一度Amazon S3などのストレージサービスに保存する必要がありません。ローカル上にある画像をそのまま使って文字起こしができるので、とても便利です。今回は以下のソースコードを使用し、サンプルとして名刺の画像を使って実行しました。
import base64
import requests
# Google Cloud Vision APIキー
API_KEY = "[7で取得したAPIキー]"
# 画像ファイルのパス
IMAGE_PATH = rr"C:\Users\Username\Desktop\meishi_card.png"
def detect_text_in_image(image_path, api_key):
"""
画像ファイルをGoogle Cloud Vision APIで解析し、テキストを検出する関数
:param image_path: 画像ファイルのパス
:param api_key: Google Cloud Vision APIのキー
:return: 検出されたテキストまたはエラーメッセージ
"""
# 画像をBase64形式にエンコード
with open(image_path, "rb") as image_file:
encoded_image = base64.b64encode(image_file.read()).decode("utf-8")
# リクエスト用のJSONデータ
request_data = {
"requests": [
{
"image": {"content": encoded_image},
"features": [{"type": "TEXT_DETECTION"}],
}
]
}
# Vision APIエンドポイントにリクエストを送信
endpoint_url = f"https://vision.googleapis.com/v1/images:annotate?key={api_key}"
response = requests.post(endpoint_url, json=request_data)
# レスポンスの解析
if response.status_code == 200:
try:
response_data = response.json()
return response_data["responses"][0]["textAnnotations"][0]["description"]
except (KeyError, IndexError):
return "Error occurred"
else:
return f"Error occurred: {response.status_code}\n{response.text}"
if __name__ == "__main__":
# 画像からテキストを検出して結果を表示
detected_text = detect_text_in_image(IMAGE_PATH, API_KEY)
print('Detected text\n----------')
print(detected_text)このコードを実行して、以下のように表示されれば成功です。かなり精度が高いです。
ラクスル株式会社
営業本部 営業一課
らくする た
ろう
営業楽刷太郎
〒000-0000
○○県○○市○○2-34-56
○○○○ビル 4F
TEL 03-0000-1234 FAX 03-0000-5678
携帯 090-0000-5678
メールアドレス sample@raksul.com
ホームページ http://raksul.com完成コード
以下のコードを使って、Cloud Vision APIで画像からテキストを抽出し、その情報をChatGPTに送信して解析結果を得る方法をご紹介します。今回はサンプルとして名刺の画像を例にしています。まず、Cloud Vision APIを使って画像からテキストを抽出し、その結果をChatGPTに送信して名刺に記載されている情報をテキストとして抽出します。なお、ChatGPT APIの取得方法については以下の記事を参考にしてください。
import base64
import requests
import json
# 処理対象の画像ファイルパス
IMAGE_PATH = r"C:\Users\Username\Desktop\meishi_card.png"
# Google Cloud Vision APIキー
VISION_API_KEY = "[Google Cloud Platform(GCP)実装編で取得したAPIキー]"
VISION_API_URL = f"https://vision.googleapis.com/v1/images:annotate?key={VISION_API_KEY}"
# OpenAI APIキー
CHATGPT_API_KEY = "[ChatGPT APIとC#(またはPython)を活用したAIメール応答システムの構築方法の記事の方法で取得したキー]"
CHATGPT_API_URL = f"https://api.openai.com/v1/chat/completions"
def extract_text_from_image(image_path):
"""
Google Cloud Vision APIを使用して画像からテキストを抽出する関数
:param image_path: 画像ファイルのパス
:return: 抽出されたテキスト
"""
# 画像をBase64形式にエンコード
with open(image_path, "rb") as image_file:
encoded_image = base64.b64encode(image_file.read()).decode("utf-8")
# リクエストデータを作成
request_data = {
"requests": [
{
"image": {"content": encoded_image},
"features": [{"type": "TEXT_DETECTION"}],
}
]
}
# Vision APIにリクエストを送信
response = requests.post(VISION_API_URL, json=request_data)
if response.status_code == 200:
response_data = response.json()
try:
detected_text = response_data["responses"][0]["textAnnotations"][0]["description"]
return detected_text
except (KeyError, IndexError):
return "テキストが検出されませんでした。"
else:
print(f"Vision API Error: {response.status_code}")
print(response.text)
return None
def send_text_to_chatgpt(text):
"""
ChatGPTにテキストを送信して解析結果を取得する関数
:param text: 送信するテキスト
:return: ChatGPTからの応答
"""
# プロンプトを作成
prompt = f"以下のテキストを解析し、名刺に記載された情報を抽出してください:\n\n{text}"
# リクエストデータを作成
request_body = {
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
],
"temperature": 0
}
# HTTPリクエストヘッダー
headers = {
"Authorization": f"Bearer {CHATGPT_API_KEY}",
"Content-Type": "application/json"
}
# ChatGPT APIにリクエストを送信
response = requests.post(CHATGPT_API_URL, headers=headers, data=json.dumps(request_body))
if response.status_code == 200:
response_data = response.json()
return response_data['choices'][0]['message']['content']
else:
print(f"ChatGPT API Error: {response.status_code}")
print(response.text)
return None
if __name__ == "__main__":
# 画像からテキストを抽出
detected_text = extract_text_from_image(IMAGE_PATH)
if detected_text:
print("Detected text:\n----------")
print(detected_text)
# 抽出したテキストをChatGPTに送信
chatgpt_response = send_text_to_chatgpt(detected_text)
print("\n\nChatGPTからの応答:\n----------")
print(chatgpt_response)
実行後、コンソールに以下のような結果が表示されます。
Detected text:
----------
ラクスル株式会社
営業本部 営業一課
らくする た
ろう
営業楽刷太郎
〒000-0000
○○県○○市○○2-34-56
○○○○ビル 4F
TEL 03-0000-1234 FAX 03-0000-5678
携帯 090-0000-5678
メールアドレス sample@raksul.com
ホームページ http://raksul.com
ChatGPTからの応答:
----------
会社名: ラクスル株式会社
部署: 営業本部 営業一課
名前: 営業楽刷太郎
住所: 〒000-0000 ○○県○○市○○2-34-56 ○○○○ビル 4F
電話番号: 03-0000-1234
FAX番号: 03-0000-5678
携帯電話番号: 090-0000-5678
メールアドレス: sample@raksul.com
ホームページ: http://raksul.comまとめ
いかがでしたでしょうか?今回は少し回り道をしましたが、無事に完成できてよかったです。今回はAmazon Web Services(AWS)とGoogle Cloud Platform(GCP)の両方を使ってみましたが、それぞれに良い点と悪い点がありました。
特にAWSは設定が少し複雑で、初心者にとっては難しい部分が多いと感じました。ただ、実際に実務目線で考えればにはセキュリティの設定が細かくできる点が非常に魅力的でした。しかし、開発者としてはAWSの設定を手動で触る必要があり、少しストレスを感じました。さらにAWS CLIをインストールし、C:\Users\ユーザー名\.awsに情報を入力する必要があり、初めてコードを読むときにはAWSに関する知識がないと理解しづらいと感じました。
一方、Google Cloud Platform(GCP)は設定がとても簡単で、わかりやすい印象を受けました。特に開発がしやすく、APIキーを設定するだけでコードがシンプルでわかりやすくなります。
今回OCR(光学式文字認識)を使用する際、AWSのAPIは開発要件を満たしておらず、最終的にGCPを選びましたが、他の開発で使う場合はAWSとGCPを比較検討するのも良いかもしれません。どちらにも強みがあり、プロジェクトに合わせて選択することが重要だと感じました。なお、両者も今回紹介したAPI以外もたくさんのサービスを提供しており、また別の機会に紹介したいと思います。
それでは、また!
参考文献
- OCRとは~業務効率ツールとして注目| リコー
- クラウドシェアはAWS・Azureで半数超!どちらを選ぶべき?|コラム|クラウドソリューション|サービス|法人のお客さま|NTT東日本
- 【初心者向け】Amazon Rekognitionの機能を試してみた #Python – Qiita
- Pythonを使ってAmazon S3にファイルをアップロードする #AWS – Qiita
- イメージ内のテキストの検出 – Amazon Rekognition
- AWS Amazon Rekognition の マネージドポリシー – Amazon Rekognition
- 通常ビジネス_横_シンプル | 名刺の無料デザインテンプレート | 印刷のラクスル
- Google Cloud Vision APIのOCRを使ってPythonから文字認識する方法 | Valmore
- Cloud Vision API に対する認証 | Vision API Product Search | Google Cloud
- 画像内のテキストを検出する | Cloud Vision API | Google Cloud
- 画像内の手書き文字を検出する | Cloud Vision API | Google Cloud
TEXT BY
TIGER RACK
タイガーラック編集部


このカテゴリの最新記事
2023.04.21
2024.02.09
2025.01.23
2026.03.05






